Retour aux blogs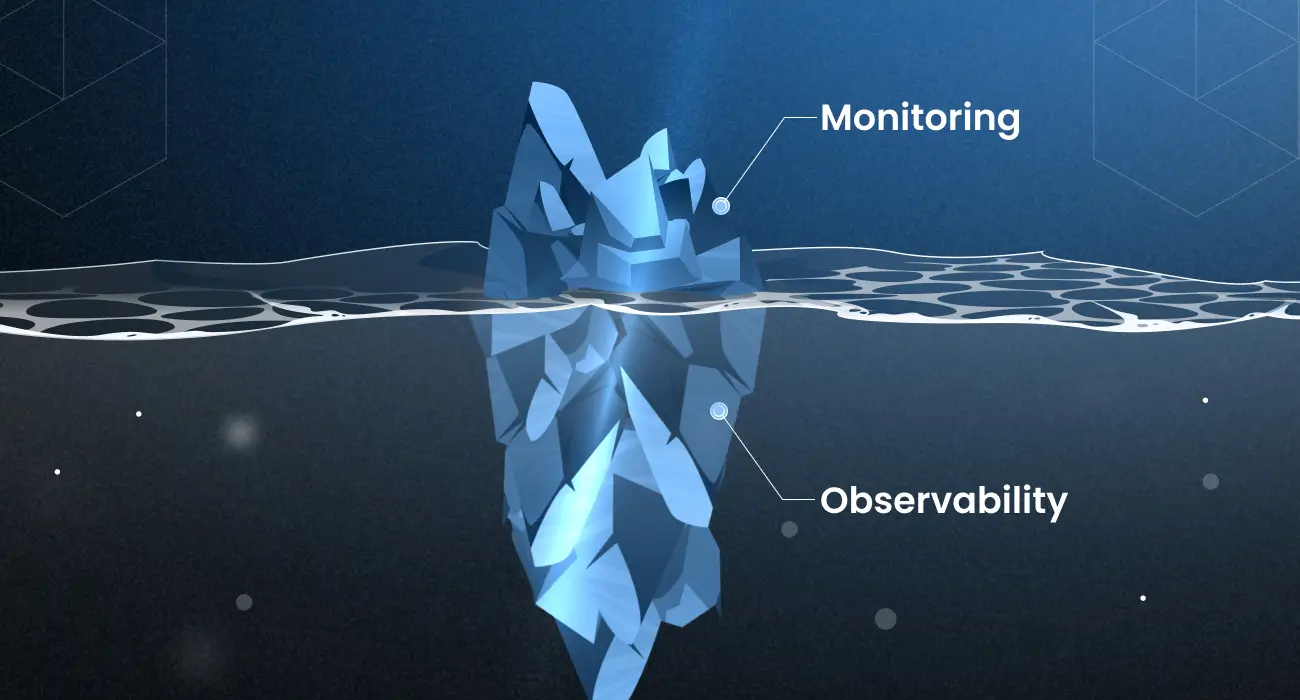
Observabilite
Monitoring & Observabilite avec Grafana : Ce qui change en 2026
13 Mars 2026
10 min de lecture
GrafanaObservabiliteMonitoringOpenTelemetrySRELGTM
Le monitoring detecte les pannes apres coup. L'observabilite moderne les anticipe avant l'impact utilisateur. Decouvrez les piliers, la stack LGTM et les tendances 2026 autour de Grafana.
Le monitoring classique detecte les pannes apres qu'elles arrivent. L'observabilite moderne les anticipe avant que l'utilisateur ne les remarque. C'est le changement fondamental que vivent les equipes infrastructure en 2026 et il redefinit completement la maniere dont on concoit, surveille et opere un systeme en production.
Les 3 piliers de l'observabilite
Tout commence par comprendre ce qu'on collecte. L'observabilite repose sur trois signaux complementaires :
- Metriques : des donnees numeriques horodatees comme le CPU, la memoire, la latence et le taux d'erreur. C'est le socle historique du monitoring. Rapides a collecter et faciles a alerter, mais elles ne racontent qu'une partie de l'histoire.
- Logs : les enregistrements detailles de ce qui s'est passe dans le systeme. Indispensables pour comprendre le contexte d'une anomalie et reconstituer une sequence d'evenements.
- Traces : le signal le plus recent et encore sous-exploite. Les traces suivent une requete de bout en bout a travers des dizaines de microservices, revelant exactement ou le temps est perdu et pourquoi. Aujourd'hui, seulement 57% des equipes les exploitent alors qu'elles sont essentielles dans toute architecture distribuee.
C'est la combinaison des trois qui transforme un outil de monitoring en veritable plateforme d'observabilite.
Grafana : bien plus qu'un outil de dashboards
Grafana est devenu la couche de visualisation universelle des stacks modernes. Sa force principale : se connecter a tout, Prometheus, Loki, Tempo, InfluxDB, Elasticsearch, PostgreSQL, et unifier ces sources dans une interface coherente. Une seule fenetre pour voir l'ensemble de l'infrastructure, en temps reel.
Mais les evolutions 2025-2026 vont bien au-dela de la visualisation :
- Grafana Assistant : un agent IA integre dans Grafana Cloud pour interroger les donnees, construire des dashboards et diagnostiquer des incidents en langage naturel, sans maitriser PromQL ou LogQL.
- Knowledge Graph : une carte intelligente qui connecte automatiquement metriques, logs, traces et profils de performance pour une vue full-stack et une navigation rapide de l'anomalie a la cause.
- RCA Workbench : un poste de travail dedie a l'analyse post-incident, qui consolide anomalies, dependances et timelines pour reduire fortement le temps moyen de resolution.
- Adaptive Telemetry : une suite qui filtre, echantillonne et priorise les donnees collectees afin de maitriser les volumes sans perdre de visibilite sur l'essentiel.
Les 4 tendances qui redefinissent le secteur
L'IA passe en production : 84% des organisations ont deja pilote l'IA appliquee a l'observabilite. En 2026, ce n'est plus experimental. Detection predictive d'anomalies, analyse automatique de cause racine et remediation autonome entrent dans les workflows standards des equipes SRE.
OpenTelemetry s'impose comme standard universel : le debat est clos. OpenTelemetry est supporte nativement par AWS, GCP, Azure et les outils majeurs. Les equipes qui n'ont pas encore migre accumulent une dette technique croissante. 79% des organisations l'ont deja adopte ou sont en cours de migration.
Observabilite des couts et de l'impact carbone : la telemetrie ne sert plus seulement a mesurer la disponibilite. Elle s'applique aussi aux couts cloud et a l'empreinte carbone des workloads. 53% des organisations europeennes mesurent deja leur impact environnemental via leurs outils d'observabilite.
Les SLOs deviennent un outil de pilotage business : 86% des equipes definissent des SLOs. En 2026, ils remontent au niveau direction, influencent les priorites de sprint et deviennent le langage commun entre equipes techniques et produit.

La stack de reference : LGTM
La combinaison qui s'est imposee comme standard open source :
- Loki : aggregation et stockage des logs
- Grafana : visualisation, alertes et exploration unifiees
- Tempo : stockage et requetage des traces distribuees
- Mimir : stockage de metriques Prometheus a grande echelle
Completee par Prometheus, Alertmanager et Pyroscope, cette stack couvre l'integralite des besoins d'observabilite sans dependance a un fournisseur proprietaire. 75% des praticiens citent d'ailleurs la neutralite vis-a-vis des fournisseurs comme critere decisif dans le choix de leurs outils.
Conclusion
L'observabilite n'est plus un sujet reserve aux equipes infrastructure. Elle est devenue un avantage competitif. Les organisations qui investissent aujourd'hui dans une stack solide, centree sur Grafana, ouverte et pilotee par l'IA, seront celles qui reagiront le plus vite demain, qui maitriseront leurs couts cloud et qui offriront la meilleure experience a leurs utilisateurs.
Le prochain incident dans votre infrastructure est inevitable. La vraie question est : est-ce que vous le verrez venir ?